# 七、基于语法树的词法分析和解析
在上一章节中,你探索了如何从各类来源中读取 Python 文本。接下来其需要被转换为编译器可以使用的结构,这个过程被称为**解析(parsing)**:
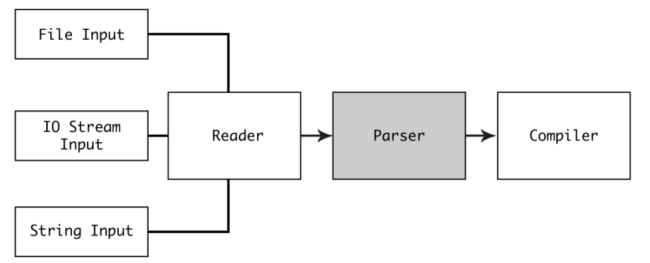 在本章节,你将继续探索文本是如何被解析为一个可以编译的逻辑结构。
CPython 会使用\*\*具象语法树(CST)**和**抽象语法树(AST)\*\*两种结构来分析代码。
在本章节,你将继续探索文本是如何被解析为一个可以编译的逻辑结构。
CPython 会使用\*\*具象语法树(CST)**和**抽象语法树(AST)\*\*两种结构来分析代码。
 解析过程分为两部分:
1. 使用\*\*解析器-分词器(parser-tokenizer)**或者**词法分析器(Lexer)\*\*创建具象语法树;
2. 通过使用\*\*解析器(parser)\*\*从具象语法树创建出抽象语法树。
这两个步骤是许多语言中都会使用到的常见范式。
解析过程分为两部分:
1. 使用\*\*解析器-分词器(parser-tokenizer)**或者**词法分析器(Lexer)\*\*创建具象语法树;
2. 通过使用\*\*解析器(parser)\*\*从具象语法树创建出抽象语法树。
这两个步骤是许多语言中都会使用到的常见范式。